A Beautiful Solution?
^^Perhaps^^
For various reasons me and my team hadn't been spending a lot of time at the coal face, coding. From spikes, POCs and analysis to release activity - coding opportunities have been few and far between. Thankfully this changed over the last couple of weeks.
As part of the Payments Platform we have been given the opportunity to chip away at some of the Legacy processes to provide more flexibility in our Payments offering. Part of this process see's us hoping to consolidate some existing logic to manage the integration with a 3rd party Payment Solution Provider more flexibly. Specifically around handling particular types of payment which are handled differently based on certain criteria such as a customers Billing country, what currency they are paying with and the card type they are using.
Stuck
In essence the work we are carrying out is a redesign and re-factor of some logic which is spread out in a number of places. Bringing it all in, has been both interesting and frustrating.
Maybe its because of the lack of practice but I couldn't quite nail a solution (to a part of the problem) until about a week after starting the work.
I'd started out test first, using TDD to drive out an initial solution, which I was sort of happy with, and then re-factored - went a bit mad - duplicated loads of tests and then had lost the essence of a simple solution. As I wasn't happy, I made a V2 of my work, left all of - what had become sociable tests - in place and started again. I ended up with real clarity, no over-engineering and a solution I am really happy with.
The essence of the problem
When filtering data , there are a number of options available.
Typically if the data is stored in SQL (perhaps relationally - but not always) , querying and filtering can easily be performed in a stored procedure (or data layer). Certainly at the cost of having business logic in the DB (usually a pretty poor choice), amongst other trade-offs.
Conversely a denormalised bit of data stored in a document store or - again - in SQL can be retrieved and then worked on in memory and up in the vernacular of the UL of a domain using LINQ and , giving a nice opportunity to easily test behaviour and nail requirements around a business critical process.
The existing solution, we are augmenting, used some pretty meaty LINQ queries. Now, arguably for some, this may suffice and do the job, but due to the number of things needed to filter on and various conditions, some pretty "all encompassing" LINQ 'WHERE' statements were being used with comments. Coupled with there were no tests for some of the behaviour, some of it seemed coincidental.
The comments alone are enough to make you question the clarity of a design and are well documented as a marker of a code smell in a lot of situations (but not all of course).
Me and my colleagues also noticed there were lots of null checks thrown in too. We all thought - we can do better than this! I lobbied for this task and was certain I'd knock something out quickly. I struggled!
My first approach saw me using the decorator pattern or at least - a bastardised version of it. The basic concept is illustrated below. In fact the approach can be visualised as moving some data through a pipeline of filters, each filter being stateless and all working toward refining some data to a reduced set. I talked about this kind of approach when mentioning folding in an earlier post. This is a functional programming technique.
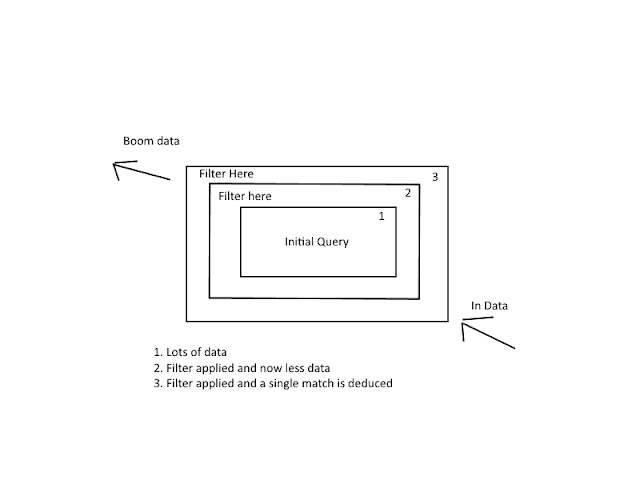
In code my first attempt was facilitated by the code below:
In the snippet above I have an interface that takes the seed collection (the original query) in the first argument - only the first filter in the chain would work on this.
The other arguments are values which are needed to drive the filtering, all of this information has to go down so that each filter can use what it needs. This could be simplified by applying Extract/Introduce Parameter Object to the parameters.
Subsequent filters just work on the results from previous filters who have their Execute method invoked within a filters Execute method. The other filter being a dependency of course.
Only one filter implementation is shown here, the currency filter. Its Execute method dictated by the interface, applies any filtering and returns the result for the next filter to do its thing (if there is one configured).
Each filter is stateless, in the end after applying a number of filters, an input set is reduced to just one matching value based on various criteria.
Setting up a "chain" of filters would look like:
Now, this worked but after review by my colleague, the fact I'd gone out of my way to encapsulate the filters as separate classes, kind of indicated that the filters should be usable by him as standalone autonomous bits of logic and this is exactly what he wanted to do as he had some similar filtering which only required some of the filters I'd made. Fair enough.
With a few tweaks this would work. The problem was that with the dependency of the filter up in the constructor without some kind of null object pattern or specific handling to check for nulls or handle setting up the chain of filters, things would break if composed in the wrong way. That is, for example, if he wanted to use a filter but didn't want to chain a specific child filter.
As well as a set of scenario driven tests for the domain service, I'd written tests for each filter and in so doing duplicated lots of test. I'd not quite implemented what I desired.
I started looking at Haskell list comprehensions and thinking about a functional way to tackle the problem and came across a post on S/O which was exactly what I was looking for. In essence I could use a left-fold and have my filters called one after another with a LINQ extension method called Aggregate which - like my solution - takes a seed but - unlike my solution - handles 'accumulating' or keeping track of the result of applying filters without the need to hand-crank any other classes. Composition looks like below. A list of methods are used to impose filtering with the heavy lifting done by a bit of LINQ as we can see below in the next snippet.
Below, the Aggregate function is called which takes a seed (our initial data to be filtered - number 1 in the diagram above), a lambda (or anonymous function) representing an accumulator method, which matches the signature of the methods in the filters list (numbers 2 and 3 in the diagram above).
It then applies each of the methods - composed above - in turn. Running each filter and passing its result, via the accumulator to the next filter, eventually pushing out a much more refined result adhering to the nip and tuck that the filters imposed along the way.
Summary
I really like the elegance of this solution. Yes it is simple (you may wonder why so many lines were devoted to something which may not have even been given a second glance on what you are working on) and there are yet simpler ways to tackle our problem, the filters could just be looped over for example (or even revert to clunkier LINQ queries). It just struck me as, erm, nice. You may well disagree. If so, please let me know in the meantime I might do a V3 and just filter down in the persistence layer :)
For various reasons me and my team hadn't been spending a lot of time at the coal face, coding. From spikes, POCs and analysis to release activity - coding opportunities have been few and far between. Thankfully this changed over the last couple of weeks.
As part of the Payments Platform we have been given the opportunity to chip away at some of the Legacy processes to provide more flexibility in our Payments offering. Part of this process see's us hoping to consolidate some existing logic to manage the integration with a 3rd party Payment Solution Provider more flexibly. Specifically around handling particular types of payment which are handled differently based on certain criteria such as a customers Billing country, what currency they are paying with and the card type they are using.
Stuck
In essence the work we are carrying out is a redesign and re-factor of some logic which is spread out in a number of places. Bringing it all in, has been both interesting and frustrating.
Maybe its because of the lack of practice but I couldn't quite nail a solution (to a part of the problem) until about a week after starting the work.
I'd started out test first, using TDD to drive out an initial solution, which I was sort of happy with, and then re-factored - went a bit mad - duplicated loads of tests and then had lost the essence of a simple solution. As I wasn't happy, I made a V2 of my work, left all of - what had become sociable tests - in place and started again. I ended up with real clarity, no over-engineering and a solution I am really happy with.
The essence of the problem
When filtering data , there are a number of options available.
Typically if the data is stored in SQL (perhaps relationally - but not always) , querying and filtering can easily be performed in a stored procedure (or data layer). Certainly at the cost of having business logic in the DB (usually a pretty poor choice), amongst other trade-offs.
Conversely a denormalised bit of data stored in a document store or - again - in SQL can be retrieved and then worked on in memory and up in the vernacular of the UL of a domain using LINQ and , giving a nice opportunity to easily test behaviour and nail requirements around a business critical process.
The existing solution, we are augmenting, used some pretty meaty LINQ queries. Now, arguably for some, this may suffice and do the job, but due to the number of things needed to filter on and various conditions, some pretty "all encompassing" LINQ 'WHERE' statements were being used with comments. Coupled with there were no tests for some of the behaviour, some of it seemed coincidental.
The comments alone are enough to make you question the clarity of a design and are well documented as a marker of a code smell in a lot of situations (but not all of course).
Me and my colleagues also noticed there were lots of null checks thrown in too. We all thought - we can do better than this! I lobbied for this task and was certain I'd knock something out quickly. I struggled!
My first approach saw me using the decorator pattern or at least - a bastardised version of it. The basic concept is illustrated below. In fact the approach can be visualised as moving some data through a pipeline of filters, each filter being stateless and all working toward refining some data to a reduced set. I talked about this kind of approach when mentioning folding in an earlier post. This is a functional programming technique.
In code my first attempt was facilitated by the code below:
In the snippet above I have an interface that takes the seed collection (the original query) in the first argument - only the first filter in the chain would work on this.
The other arguments are values which are needed to drive the filtering, all of this information has to go down so that each filter can use what it needs. This could be simplified by applying Extract/Introduce Parameter Object to the parameters.
Subsequent filters just work on the results from previous filters who have their Execute method invoked within a filters Execute method. The other filter being a dependency of course.
Only one filter implementation is shown here, the currency filter. Its Execute method dictated by the interface, applies any filtering and returns the result for the next filter to do its thing (if there is one configured).
Each filter is stateless, in the end after applying a number of filters, an input set is reduced to just one matching value based on various criteria.
Setting up a "chain" of filters would look like:
Now, this worked but after review by my colleague, the fact I'd gone out of my way to encapsulate the filters as separate classes, kind of indicated that the filters should be usable by him as standalone autonomous bits of logic and this is exactly what he wanted to do as he had some similar filtering which only required some of the filters I'd made. Fair enough.
With a few tweaks this would work. The problem was that with the dependency of the filter up in the constructor without some kind of null object pattern or specific handling to check for nulls or handle setting up the chain of filters, things would break if composed in the wrong way. That is, for example, if he wanted to use a filter but didn't want to chain a specific child filter.
As well as a set of scenario driven tests for the domain service, I'd written tests for each filter and in so doing duplicated lots of test. I'd not quite implemented what I desired.
I started looking at Haskell list comprehensions and thinking about a functional way to tackle the problem and came across a post on S/O which was exactly what I was looking for. In essence I could use a left-fold and have my filters called one after another with a LINQ extension method called Aggregate which - like my solution - takes a seed but - unlike my solution - handles 'accumulating' or keeping track of the result of applying filters without the need to hand-crank any other classes. Composition looks like below. A list of methods are used to impose filtering with the heavy lifting done by a bit of LINQ as we can see below in the next snippet.
Below, the Aggregate function is called which takes a seed (our initial data to be filtered - number 1 in the diagram above), a lambda (or anonymous function) representing an accumulator method, which matches the signature of the methods in the filters list (numbers 2 and 3 in the diagram above).
It then applies each of the methods - composed above - in turn. Running each filter and passing its result, via the accumulator to the next filter, eventually pushing out a much more refined result adhering to the nip and tuck that the filters imposed along the way.
Summary
I really like the elegance of this solution. Yes it is simple (you may wonder why so many lines were devoted to something which may not have even been given a second glance on what you are working on) and there are yet simpler ways to tackle our problem, the filters could just be looped over for example (or even revert to clunkier LINQ queries). It just struck me as, erm, nice. You may well disagree. If so, please let me know in the meantime I might do a V3 and just filter down in the persistence layer :)
Missed some code snippets on first publish.....
ReplyDelete